Sentinel Hub Batch Statistical
Requesting statistical data (as shown in Statistical API tutorial) instead of entire images already reduces the amount of data we need to download and process. To make large-scale requests even more time and cost efficient one can use the Batch Statistical API, the statistical counterpart of the Batch Processing API. By using server-side parallelization it delivers results faster and more cost efficiently directly to your S3 bucket.
More information about batch processing is available at Sentinel Hub documentation pages:
Overview
The tutorial will show a small example of using the Batch Statistical API with sentinelhub-py. The process can largely be divided into:
Preparing credentials and storage,
Define and create a batch request,
Analyse, start and monitor the execution of the request,
Check results.
Imports
The tutorial requires additional packages geopandas and matplotlib that are not dependencies of sentinelhub-py.
[1]:
%matplotlib inline
import logging
import geopandas as gpd
import matplotlib.pyplot as plt
from sentinelhub import (
DataCollection,
SentinelHubBatchStatistical,
SentinelHubStatistical,
SHConfig,
monitor_batch_statistical_job,
)
from sentinelhub.aws.batch import AwsBatchStatisticalResults
from sentinelhub.data_utils import get_failed_statistical_requests, statistical_to_dataframe
1. Credentials and Storage
1.1 Sentinel Hub credentials
Credentials for Sentinel Hub should be set in the same way as for regular statistical requests. Please check configuration instructions about how to set up your Sentinel Hub credentials.
[3]:
config = SHConfig()
if not config.sh_client_id or not config.sh_client_secret:
print("Warning! To use Batch Statistical API, please provide the credentials (OAuth client ID and client secret).")
1.2 AWS credentials
Batch Statistical API uses S3 buckets for both input and output. It can be the same bucket for both, or two completely separate buckets. Whichever it might be, the Batch Statistical Request needs permissions for reading and writing to buckets.
Due to security reasons we strongly advise you to not provide your master credentials. Using a temporary IAM user, which is deleted after the batch request, is a much safer alternative. Here is the official guide on how to approach this. You need to provide the AWS Access ID and AWS Secret Key of the selected IAM user to the Batch Statistical Request.
To further improve security we also encourage you to assign a strict policy to the IAM role. The permissions it needs are GetObject, PutObject and DeleteObject, so the policy should look something like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<my-bucket>/<optional-path-to-relevant-subfolder>/*"
]
}
]
}
[4]:
AWS_ID = "my-aws-access-id"
AWS_SECRET = "my-aws-secret-key"
1.3 Preparing input
The geometries for which the Batch Statistical Request is evaluated are provided as input via a GeoPackage file on an S3 bucket. All features (polygons) in the input GeoPackage must be in the same CRS (which has to be supported by Sentinel Hub).
A custom column identifier of type string can be added to GeoPackage and its value will be available in an output file as identifier property.
For this example notebook we’ll be using the Sentinel Hub example geopackage.
Lets first take a quick glance at the example file.
[5]:
# The following lines assume that the example geopackage is downloaded to the same folder as the notebook
example_input = gpd.read_file("geopackage-example.gpkg")
example_input
[5]:
| identifier | geometry | |
|---|---|---|
| 0 | SI21.FOI.7059004001 | MULTIPOLYGON (((16.03718 46.42175, 16.03721 46... |
| 1 | SI21.FOI.7059009001 | MULTIPOLYGON (((16.04074 46.41680, 16.04081 46... |
| 2 | SI21.FOI.6620269001 | MULTIPOLYGON (((16.04012 46.41566, 16.04004 46... |
| 3 | SI21.FOI.6681475001 | MULTIPOLYGON (((16.04098 46.41634, 16.04069 46... |
| 4 | SI21.FOI.6828863001 | MULTIPOLYGON (((16.03891 46.41792, 16.03891 46... |
| ... | ... | ... |
| 359 | SI21.FOI.6741898001 | MULTIPOLYGON (((16.00068 46.41867, 16.00064 46... |
| 360 | SI21.FOI.6741894001 | MULTIPOLYGON (((15.99822 46.42195, 15.99822 46... |
| 361 | SI21.FOI.6511522001 | MULTIPOLYGON (((16.00348 46.41886, 16.00324 46... |
| 362 | SI21.FOI.6282186001 | MULTIPOLYGON (((16.01307 46.42134, 16.01308 46... |
| 363 | SI21.FOI.6651959001 | MULTIPOLYGON (((16.00946 46.41990, 16.00940 46... |
364 rows × 2 columns
We see that the example file also has custom identifiers set. We should also visualize the polygons to check everything is sensible. The geometries represent fields in north-eastern Slovenia.
[6]:
example_input.plot();
However it’s CRS is WGS84. We’d prefer to work in a CRS that uses meters as units, so let’s reproject everything to the UTM zone 33N (EPSG: 32633).
[7]:
example_input.crs
[7]:
<Geographic 2D CRS: EPSG:4326>
Name: WGS 84
Axis Info [ellipsoidal]:
- Lat[north]: Geodetic latitude (degree)
- Lon[east]: Geodetic longitude (degree)
Area of Use:
- name: World.
- bounds: (-180.0, -90.0, 180.0, 90.0)
Datum: World Geodetic System 1984 ensemble
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
[8]:
reprojected_geometries = example_input.to_crs("epsg:32633")
reprojected_geometries.crs
[8]:
<Derived Projected CRS: EPSG:32633>
Name: WGS 84 / UTM zone 33N
Axis Info [cartesian]:
- E[east]: Easting (metre)
- N[north]: Northing (metre)
Area of Use:
- name: Between 12°E and 18°E, northern hemisphere between equator and 84°N, onshore and offshore. Austria. Bosnia and Herzegovina. Cameroon. Central African Republic. Chad. Congo. Croatia. Czechia. Democratic Republic of the Congo (Zaire). Gabon. Germany. Hungary. Italy. Libya. Malta. Niger. Nigeria. Norway. Poland. San Marino. Slovakia. Slovenia. Svalbard. Sweden. Vatican City State.
- bounds: (12.0, 0.0, 18.0, 84.0)
Coordinate Operation:
- name: UTM zone 33N
- method: Transverse Mercator
Datum: World Geodetic System 1984 ensemble
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
[9]:
reprojected_geometries[:100].to_file("reprojected-geoms.gpkg")
We must now transfer the "reprojected-geoms.gpkg" file to the designated S3 bucket. It should be placed in such a way that the IAM user we’ll be using has access to it.
Each job output will be saved in a folder named after the request ID, but to keep things organized we’ll also use the output subfolder.
[10]:
INPUT_PATH = "s3://<my-bucket>/<path-to-relevant-subfolder>/reprojected-geoms.gpkg"
OUTPUT_PATH = "s3://<my-bucket>/<path-to-relevant-subfolder>/output/"
2. Make a Batch Statistical API request
Batch statistical requests are largely the same as regular statistical requests. In fact we’ll use a slightly modified version of the request in the Statistical API tutorial.
2.1 Defining the request
Since both request types are so similar we are able to make use of SentinelHubStatistical helper methods. Let us define the statistical part of the request first. We’re interested in the NDVI values of the fields in June of 2020.
[11]:
ndvi_evalscript = """
//VERSION=3
function setup() {
return {
input: [
{
bands: [
"B04",
"B08",
"dataMask"
]
}
],
output: [
{
id: "ndvi",
bands: 1
},
{
id: "dataMask",
bands: 1
}
]
}
}
function evaluatePixel(samples) {
return {
ndvi: [index(samples.B08, samples.B04)],
dataMask: [samples.dataMask]
};
}
"""
aggregation = SentinelHubStatistical.aggregation(
evalscript=ndvi_evalscript,
time_interval=("2020-06-01", "2020-06-30"),
aggregation_interval="P1D",
resolution=(10, 10),
)
histogram_calculations = {"ndvi": {"histograms": {"default": {"nBins": 20, "lowEdge": -1.0, "highEdge": 1.0}}}}
input_data = [SentinelHubStatistical.input_data(DataCollection.SENTINEL2_L1C, maxcc=0.8)]
Now we define the storage specifications. For this we can use helper method SentinelHubBatchStatistical.s3_specification that generates a dictionary specifying an S3 access. One can also write all of the dictionaries by hand, as long as they follow the official specifications.
[12]:
input_features = SentinelHubBatchStatistical.s3_specification(INPUT_PATH, AWS_ID, AWS_SECRET)
output = SentinelHubBatchStatistical.s3_specification(OUTPUT_PATH, AWS_ID, AWS_SECRET)
2.2 Creating the request
We first create a Batch Statistical client with which we’ll manage any requests.
[13]:
client = SentinelHubBatchStatistical(config)
We then create a new request with the create method. If we have any SentinelHubStatistical requests on hand, we can use them to create a batch statistical request via the create_from_request method. The geometry of the original request is then substituted with the input file.
[14]:
# Note: all arguments must be passed as keyword arguments
request = client.create(
input_features=input_features,
input_data=input_data,
aggregation=aggregation,
calculations=histogram_calculations,
output=output,
)
request
[14]:
BatchStatisticalRequest(
request_id=4700adcb-b0fc-44b4-80df-d97ae1f33ec3
created=2022-08-26 08:40:36.127266+00:00
status=BatchRequestStatus.CREATED
user_action=BatchUserAction.NONE
cost_pu=0.0
completion_percentage=0
...
)
The request_id field is especially important, since most of the client methods only require the ID to work. It can also be used to continue with the same job in a different notebook or after resetting the environment.
The BatchStatisticalRequest class contains more than just what is listed above. You always have the option of using the to_dict and from_dict methods if you wish to see the entire content at once or need to iterate over all the values.
3. Analyse, start and monitor the request
Analysis of a request is automatically done prior to starting the job. You can also trigger it manually with the start_analysis method. While the analysis cannot infer the cost of the request (too many things to take into consideration) it does some preparations for the job and verifies the input file.
We’ll just go ahead and start the request.
[15]:
client.start_job(request)
[15]:
''
If you wish to check on the current status of your request you can use the get_status method.
[16]:
client.get_status(request)
[16]:
{'id': '4700adcb-b0fc-44b4-80df-d97ae1f33ec3',
'status': 'CREATED',
'completionPercentage': 0,
'costPU': 0.0,
'created': '2022-08-26T08:40:36.127266Z'}
We also have a utility function monitor_batch_statistical_job (and the analysis counterpart monitor_batch_statistical_analysis) that periodically checks the status and updates a progress bar.
[17]:
# To get the full output we must configure the logger first
logging.basicConfig(level=logging.INFO)
monitor_batch_statistical_job(request, config=config, analysis_sleep_time=60)
INFO:sentinelhub.api.batch.utils:Batch job has a status CREATED, sleeping for 60 seconds
INFO:sentinelhub.api.batch.utils:Batch job has a status CREATED, sleeping for 60 seconds
INFO:sentinelhub.api.batch.utils:Batch job has a status ANALYSING, sleeping for 60 seconds
INFO:sentinelhub.api.batch.utils:Batch job is running
Completion percentage: 100%|██████████| 100/100 [11:35<00:00, 6.95s/it]
[17]:
{'id': '4700adcb-b0fc-44b4-80df-d97ae1f33ec3',
'status': 'DONE',
'completionPercentage': 100,
'lastUpdated': '2022-08-26T08:55:08.962021Z',
'costPU': 6.027410152775339,
'created': '2022-08-26T08:40:36.127266Z'}
4. Check results
With the batch statistical request completed we do a quick inspection of the results. A folder with the same name as our request is located at OUTPUT_PATH and it contains multiple JSON files with results. The JSON files are named after the id of the row, not after our custom identifier, so we have files from 1.json all the way to 100.json on our bucket.
We can transfer them to the local storage with the help of AwsBatchStatisticalResults.
[18]:
LOCAL_FOLDER = "batch_output"
result_ids = range(1, 51) # let's only download half of the results for now
batch_results_request = AwsBatchStatisticalResults(
request, data_folder=LOCAL_FOLDER, feature_ids=result_ids, config=config
)
results = batch_results_request.get_data(save_data=True, max_threads=4, show_progress=True)
100%|██████████| 50/50 [00:07<00:00, 6.60it/s]
To transform the results into a Pandas dataframe we’ll borrow the helper function from the Statistical API example notebook.
[19]:
dataframe = statistical_to_dataframe(results)
dataframe
[19]:
| ndvi_B0_min | ndvi_B0_max | ndvi_B0_mean | ndvi_B0_stDev | ndvi_B0_sampleCount | ndvi_B0_noDataCount | ndvi_B0_bins | ndvi_B0_counts | interval_from | interval_to | identifier | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.019211 | 0.366078 | 0.167395 | 0.092565 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 30, 39, 29, 10,... | 2020-06-01 00:00:00+00:00 | 2020-06-02 00:00:00+00:00 | SI21.FOI.7059004001 |
| 1 | 0.296662 | 0.435169 | 0.343738 | 0.034777 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 95, 11... | 2020-06-04 00:00:00+00:00 | 2020-06-05 00:00:00+00:00 | SI21.FOI.7059004001 |
| 2 | 0.246869 | 0.710537 | 0.376068 | 0.118973 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 32, 47, 1... | 2020-06-06 00:00:00+00:00 | 2020-06-07 00:00:00+00:00 | SI21.FOI.7059004001 |
| 3 | 0.231761 | 0.693998 | 0.359988 | 0.095531 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 35, 38, 2... | 2020-06-11 00:00:00+00:00 | 2020-06-12 00:00:00+00:00 | SI21.FOI.7059004001 |
| 4 | 0.287994 | 0.624406 | 0.398957 | 0.063102 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 56, 44... | 2020-06-14 00:00:00+00:00 | 2020-06-15 00:00:00+00:00 | SI21.FOI.7059004001 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4 | 0.346312 | 0.724465 | 0.462070 | 0.109018 | 85 | 7 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 28, 30... | 2020-06-14 00:00:00+00:00 | 2020-06-15 00:00:00+00:00 | SI21.FOI.6828881001 |
| 5 | 0.392224 | 0.841591 | 0.553246 | 0.140759 | 85 | 7 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 42,... | 2020-06-19 00:00:00+00:00 | 2020-06-20 00:00:00+00:00 | SI21.FOI.6828881001 |
| 6 | 0.358235 | 0.826512 | 0.576634 | 0.125860 | 85 | 7 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 25,... | 2020-06-24 00:00:00+00:00 | 2020-06-25 00:00:00+00:00 | SI21.FOI.6828881001 |
| 7 | 0.116505 | 0.470932 | 0.286325 | 0.070432 | 85 | 7 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 45, 20, 7... | 2020-06-26 00:00:00+00:00 | 2020-06-27 00:00:00+00:00 | SI21.FOI.6828881001 |
| 8 | 0.372048 | 0.755111 | 0.546245 | 0.105469 | 85 | 7 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 6, 17,... | 2020-06-29 00:00:00+00:00 | 2020-06-30 00:00:00+00:00 | SI21.FOI.6828881001 |
450 rows × 11 columns
[20]:
failed_requests = get_failed_statistical_requests(results)
failed_requests
[20]:
[]
[21]:
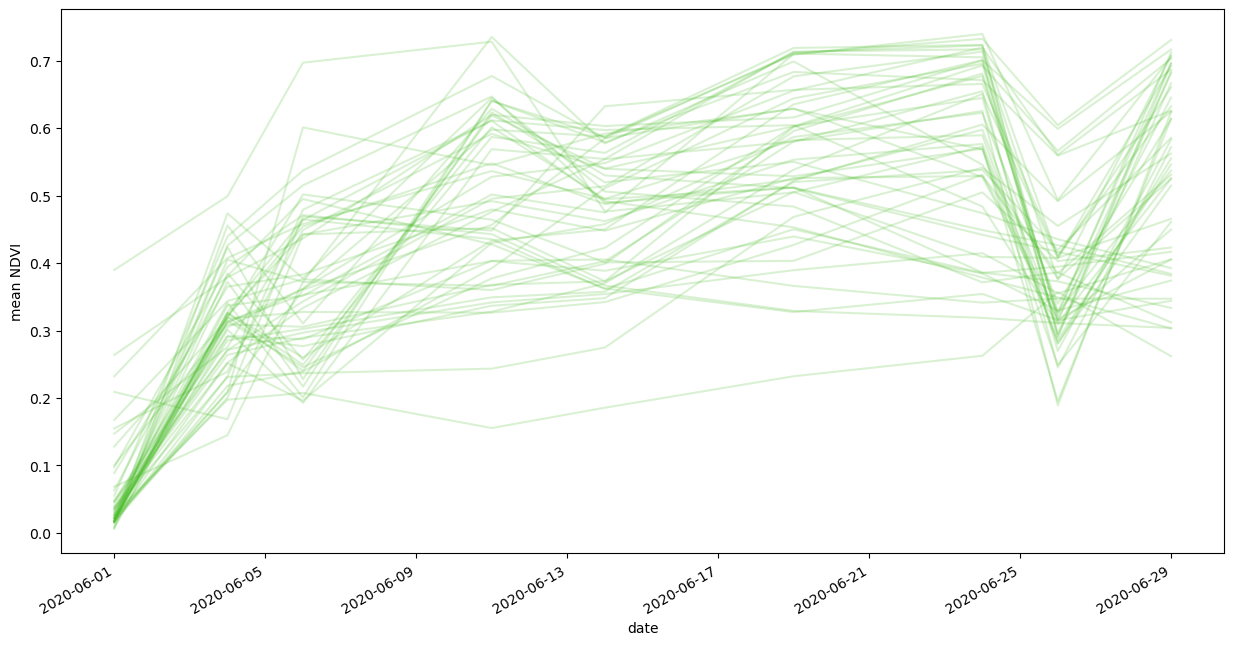
fig, ax = plt.subplots(figsize=(15, 8))
for _, group in dataframe.groupby("identifier"):
group.plot(ax=ax, x="interval_from", y="ndvi_B0_mean", color="#44BB22", alpha=0.2)
ax.get_legend().remove()
plt.ylabel("mean NDVI")
plt.xlabel("date");
[22]:
# select the data of the first geometry in the results
geom1_df = dataframe[dataframe["identifier"] == dataframe["identifier"].iloc[0]]
geom1_df
[22]:
| ndvi_B0_min | ndvi_B0_max | ndvi_B0_mean | ndvi_B0_stDev | ndvi_B0_sampleCount | ndvi_B0_noDataCount | ndvi_B0_bins | ndvi_B0_counts | interval_from | interval_to | identifier | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.019211 | 0.366078 | 0.167395 | 0.092565 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 30, 39, 29, 10,... | 2020-06-01 00:00:00+00:00 | 2020-06-02 00:00:00+00:00 | SI21.FOI.7059004001 |
| 1 | 0.296662 | 0.435169 | 0.343738 | 0.034777 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 95, 11... | 2020-06-04 00:00:00+00:00 | 2020-06-05 00:00:00+00:00 | SI21.FOI.7059004001 |
| 2 | 0.246869 | 0.710537 | 0.376068 | 0.118973 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 32, 47, 1... | 2020-06-06 00:00:00+00:00 | 2020-06-07 00:00:00+00:00 | SI21.FOI.7059004001 |
| 3 | 0.231761 | 0.693998 | 0.359988 | 0.095531 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 35, 38, 2... | 2020-06-11 00:00:00+00:00 | 2020-06-12 00:00:00+00:00 | SI21.FOI.7059004001 |
| 4 | 0.287994 | 0.624406 | 0.398957 | 0.063102 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 56, 44... | 2020-06-14 00:00:00+00:00 | 2020-06-15 00:00:00+00:00 | SI21.FOI.7059004001 |
| 5 | 0.466281 | 0.704989 | 0.595701 | 0.061266 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 11,... | 2020-06-19 00:00:00+00:00 | 2020-06-20 00:00:00+00:00 | SI21.FOI.7059004001 |
| 6 | 0.537379 | 0.752062 | 0.681036 | 0.047741 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 2020-06-24 00:00:00+00:00 | 2020-06-25 00:00:00+00:00 | SI21.FOI.7059004001 |
| 7 | 0.238012 | 0.441691 | 0.323253 | 0.055534 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 44, 54, 1... | 2020-06-26 00:00:00+00:00 | 2020-06-27 00:00:00+00:00 | SI21.FOI.7059004001 |
| 8 | 0.513155 | 0.755660 | 0.712164 | 0.034516 | 112 | 3 | [-1.0, -0.9, -0.8, -0.7, -0.6, -0.5, -0.399999... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 2020-06-29 00:00:00+00:00 | 2020-06-30 00:00:00+00:00 | SI21.FOI.7059004001 |
[23]:
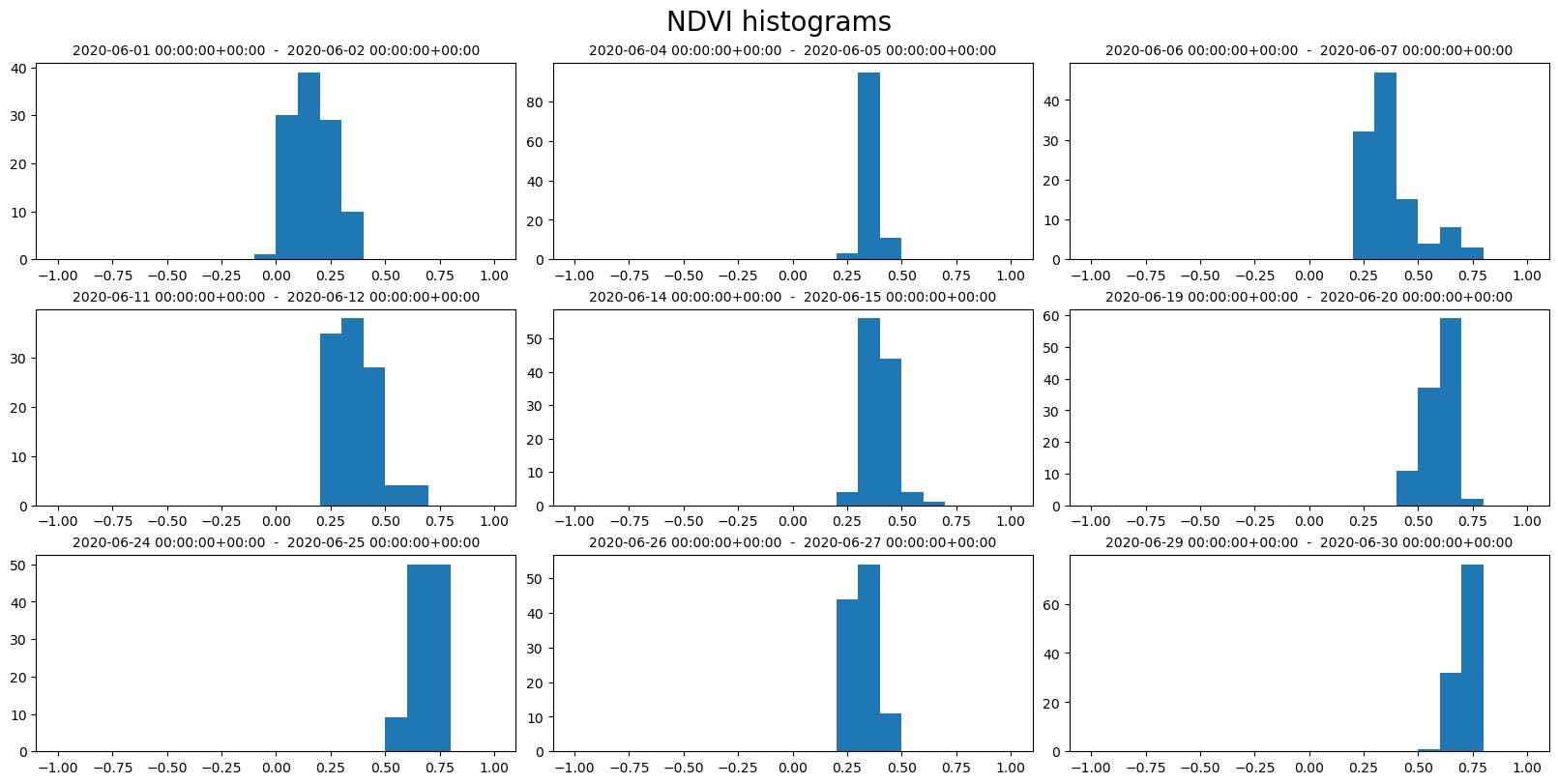
ncols = 3
nrows = 3
fig, axs = plt.subplots(ncols=ncols, nrows=nrows, figsize=(16, 8), constrained_layout=True)
fig.suptitle("NDVI histograms", fontsize=20)
for index, row in geom1_df.iterrows():
ax = axs[index // ncols][index % ncols]
bins = row["ndvi_B0_bins"]
counts = row["ndvi_B0_counts"]
ax.hist(bins[:-1], bins, weights=counts)
ax.set_title(f"{row['interval_from']} - {row['interval_to']}", fontsize=10)
[ ]: